V1 - Processing - aggregate
aggregate
- aggregate A = aggregate_function(B), … by C
- aggregate_functions:
- count(expression): counting the amount
- sum(expression): summing
- unique(expression): returning the unique variables with duplicates discarded (estimated)
- distinct(expression): returning the unique variables with duplicates discarded
- min/max/avg(expression): the minimum/maximum/average
- values(expression): converting the characters into values
- stdev(expression): the standard deviation
aggregate with by
The command aggregate assigns to A the results of the aggregate_functions over B, grouped by C. It is often followed with by, which can be thought of as the same as an SQL GROUP BY. Without by argument, aggregate over the entire table of B.
Example 1-aggregate_functions
function list()
search
let source=f("@source"), size=f("__size__"), behavior=f("@behaviors"),_time=f("@timestamp")
aggregate sourceCount=count(), sourceVolume=sum(size), behaviorCount=unique(behavior) by timebucket("1h", _time),source
end
function sourceSTD()
search
let source=f("@source"), size=f("__size__"), behavior=f("@behaviors"),_time=f("@timestamp")
aggregate sourceCount=count(), sourceVolume=sum(size), behaviorCount=unique(behavior) by timebucket("1h", _time),source
aggregate sourceSTD=stdev(sourceCount) by source
end
stream list=list()
stream sourceSTD=sourceSTD()
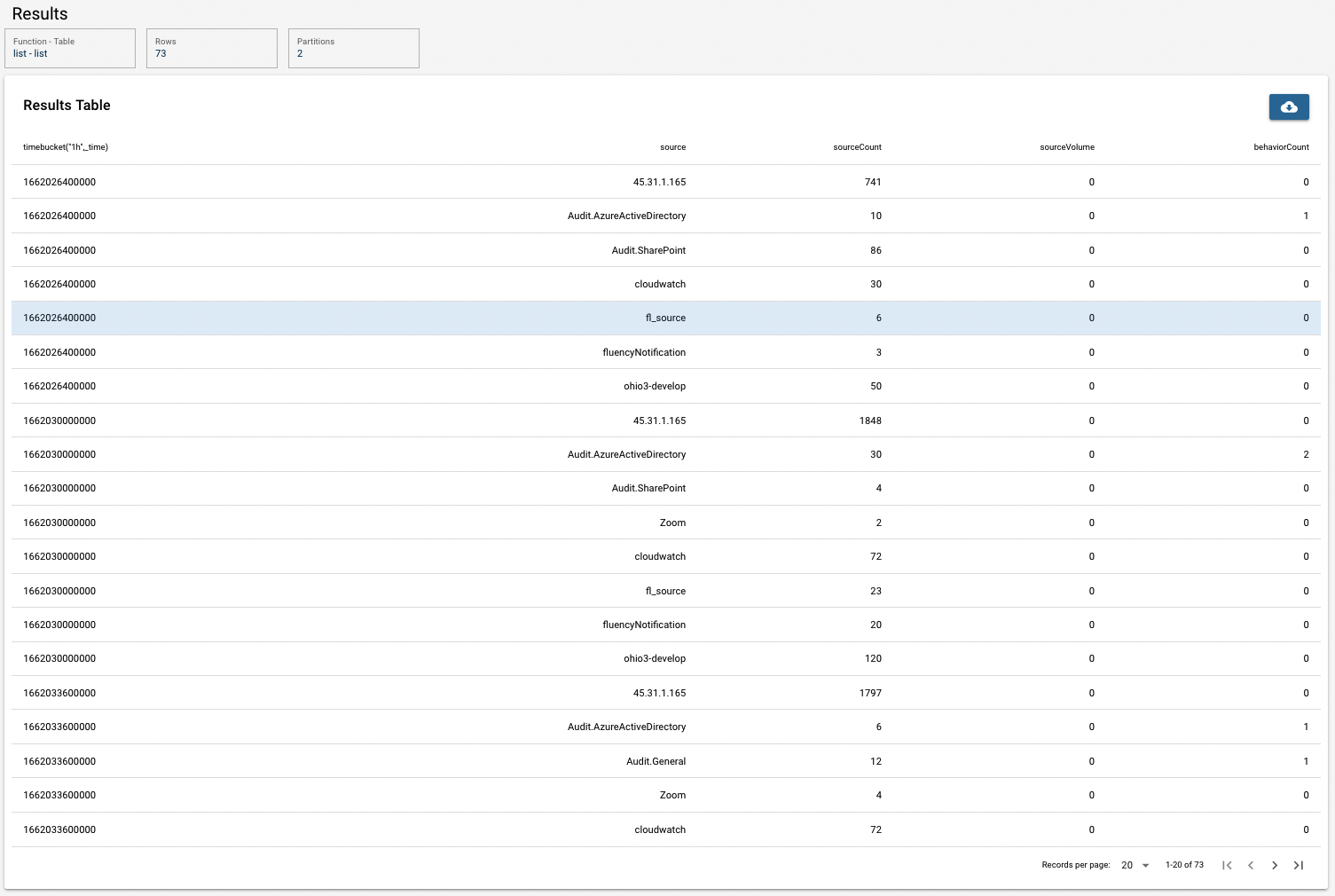
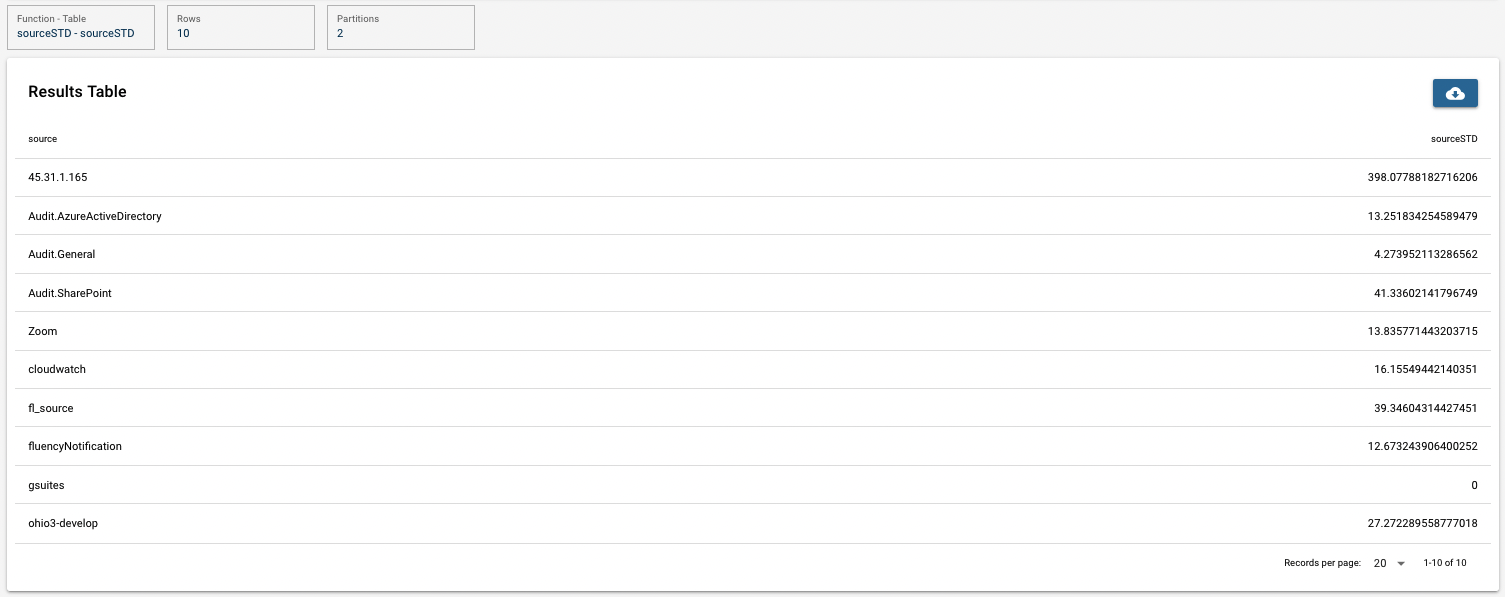
From the first result table, the total count of source, volume, and varieties of behaviors are calculated grouped by source. In the second table, based on the time series "sourceCount", its standard devaition is given.
The example above consists of two functions. After aggregate argument, other variables not included in aggregate_functions will be discarded, so the aggregate cannot be used twice in one module of FPL code (so do search; where; etc). Multiple purposes can be achieved by wrapping the corresponding codes into multiple functions.
Example 2-aggregated by time slot
let _time=f("@timestamp")
aggregate sessioncount=count() by timeslot=timebucket("1h",_time)
let iso2822=strftime("%a, %d %b %Y %T %z",timeslot)
table iso2822, sessioncount
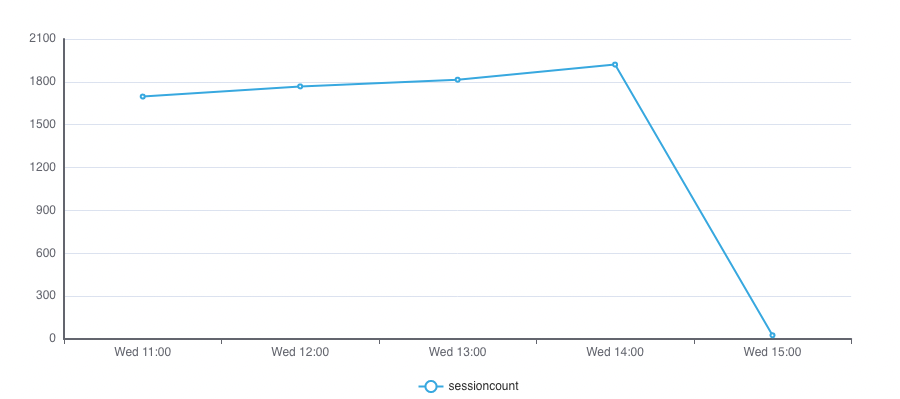
In this example, the command [timebucket](data-processing/time-related functions.html#timebucket) gives a time interval for aggregation.
Example 3-aggregated by more than one variable
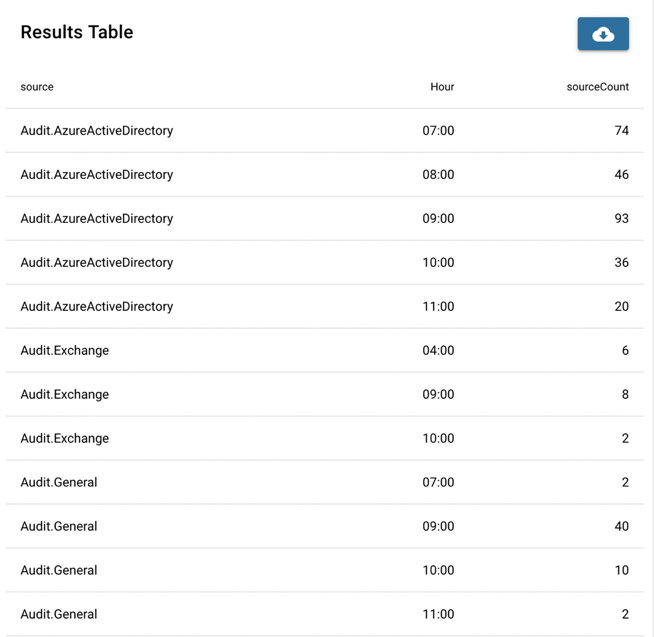
The by argument can also be followed with two terms. This means, firstly, count according to the rows of the first term (source, in the following example), then, within each row of "source", count according to the rows of "Hour".
search
let source=f("@source"),size=f("__size__"),timestamp=f("@timestamp")
let Hour=strftime("%H:%M",timebucket("1h",timestamp))
aggregate sourceCount=count() by source, Hour
aggregate without by
When a table is creating on a spreadsheet, there is often a total row that contains a total of each column. This is done in FPL by calling aggregate without a by argument.
Example 4
function s1_infected()
load resource sentinelOneAgent
let {agentID} = f("@sentinelOneAgent.translation")
let {computerName,modelName,mitigationMode,infected,appsVulnerabilityStatus} = f("@sentinelOneAgent")
aggregate total=count(), infected=count(infected), patchNeeded=count(appsVulnerabilityStatus=="patch_required")
end
stream infected_systems=s1_infected()
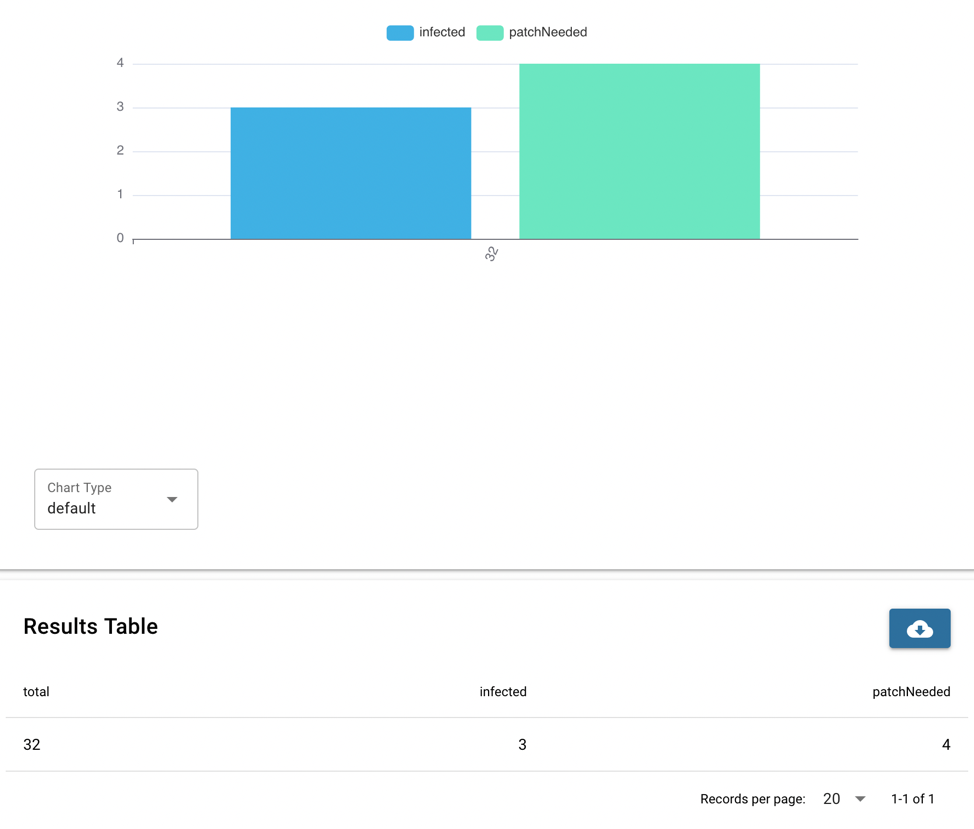
In this example, the resource of SentinelOne agents is used to create a table. We want to show the table, but we also want to total certain rows (number of infected and systems that need patches).
What really makes aggregate work is the logic inside the aggregate function count().
• When we want to count all the rows, we just use count with no parameters, count().
• The field infected is of type boolean (true or false), so we can just pass that into the argument directly, count(infected).
• Lastly we can pass an expression. When a patch is required, the term patch_required is the value for appsVulnerabilityStatus. In this case we pass the expression to test the match inside count: appsVulnerabilityStatus==”patch_required”.